
Estimated reading time: 15min (scan) – 35min (dive)
TLDR — LTV, CAC, and why teams keep fixing the wrong thing
- We should treat LTV:CAC as a signal, not a verdict. It tells us we’re under pressure. It doesn’t tell us where the leak is.
- When CAC rises, the reflex is to chase the most visible knobs — bids, budgets, creatives. That reflex is human. It’s also how teams burn runway.
- The fastest way out usually starts downstream: activation, monetization design, and lifecycle. Those are the levers that make higher CAC tolerable — because they raise LTV.
- When CAC spikes, we should first separate two root causes: product changes we made vs. platform changes that happened to us.
- If we can’t connect acquisition tests to activation, week-4 retention, and revenue, we’re not optimizing — we’re just guessing.
- Demand Testing is our shortcut to truth: we advertise the feature before we build it, then pair the signal with qual, and forecast payback. That keeps engineering time safe.
CAC creeping up on you?
You open your dashboard. Spend is up. CAC is squeezing LTV. Someone senior wants answers by tomorrow. This moment is stressful because it’s high stakes — and because most growth systems often reward fast stories over true ones.
MAVAN VP of Growth Sam McLellan put a sharp point on what we see in the wild: CAC spikes often come from two places. One is internal — a product team changes the trial or onboarding flow (turn it off, stretch it from three days to 30, change the conversion moment). CAC jumps because the low-risk entry just disappeared.
The other is external — the platform changes its behavior and your campaign changes in stride overnight. Sam points to Meta as an example. When Meta expanded inventory, it suddenly meant you could suddenly run harder into placements you didn’t expect, with traffic quality you didn’t ask for. Either way, your budget moves before your team does.
When CAC jumps, we ask one question first: did we change the product — or did the platform change us? Over the course of this article, we’ll dive into what we do in these situations — along with everything else CAC and LTV related.
What LTV:CAC actually tells you vs. what it hides
LTV is the lifetime value of a customer — the expected gross margin you’ll get from a user over their lifetime. CAC is the cost to acquire that customer. The LTV:CAC ratio compares those two numbers. Many investors and operators use ~3.0 as a shorthand benchmark for health — but that target alone doesn’t solve anything.
Ultimately, the ratio is a signal, not a roadmap. It tells us that something changed, and we need to learn where. It does not tell us whether the fix lives in bidding, onboarding, pricing, retention, creative, or measurement.
That distinction matters because pressure makes teams grab the nearest lever. Under board heat, we’ve watched smart teams treat CAC like a moral failing. Then they overcorrect. They slash spend, starve learning, and call it discipline. Or they keep spending, hope it normalizes, and call it confidence. Both moves are understandable self-protection. But neither is a plan that will actually improve things.
Sam frames the competitive reality clearly: acquisition markets include players with massive budgets, and we can’t assume we’ll always buy customers cheaply. The job is not to find the cheapest CAC. The job is to build a system that can sustain higher CAC when the market tightens.
That system often lives in LTV.

The accounting choices that create fake certainty
Here’s where teams accidentally lie to themselves — not because they’re dishonest, but because the incentives reward fast answers.
1) Teams pick an LTV definition that flatters the story. Sam’s remedy to this is practical: he uses gross LTV, and he removes the platform fees that hit immediately (like Apple and Google fees). That keeps the math grounded in the money you actually keep. He also anchors LTV to a company’s real payback comfort zone — because good LTV depends on how long you can wait to get cash back.
2) Teams pick a CAC definition that hides the full cost. Sam pushes for fully loaded CAC — as fully loaded as you can reasonably make it. That means tools, personnel, and the real costs of running growth. It feels more painful, but it protects runway. It also forces hard calls sooner, before you spend money you cannot earn back.
3) Teams ignore the prerequisites for honest math. Fully loaded CAC and defensible LTV require attribution and financial modeling that can survive scrutiny. Sam’s been inside startups where teams grow for years without that foundation. Then a platform change hits, CAC jumps, and everyone realizes they can’t explain what’s happening with confidence.
What the ratio hides: time and shape
LTV:CAC can look fine while your payback window becomes increasingly compromised. It can also look bad while your cohorts improve, just slowly. That’s why we don’t stop at the ratio. We look at:
- Payback window trend (not just the final ratio)
- Cohort LTV curves (shape over time, not a single point)
- Retention curves (where the drop happens, and for whom)
- Marginal CAC by channel (where the pressure concentrates)
If we only track the ratio, we’re just storytelling. If we track the curves, we uncover truth.
The two CAC spikes we see — and the 48-hour response
Most CAC spikes are not mysteries. They’re misclassification.
In Sam’s words, there are two buckets: things we control inside our ecosystem, and things the ad platforms change overnight. The trick is naming which one you’re in fast — because the fixes don’t overlap.
Product-driven CAC spikes
The cleanest example is a subscription app’s onboarding or trial flow. Teams optimize it constantly. They toggle the trial on or off. They stretch it from three days to 30. Those are not small changes. They reshape conversion dynamics.
Sam’s point is blunt: if you turn off the free trial, CAC can jump hard. Now users either convert immediately or they don’t. The longer-tail conversion window disappears.
The leadership mistake here is emotional. We assume marketing got worse. Sometimes, marketing didn’t change at all. We just made the product harder to say yes to.
What we do in the first 48 hours for product-driven CAC spikes:
- Pull a timeline of product changes. Don’t rely on memory.
- Compare cohorts before and after the change. Focus on activation and paid conversion.
- Decide if we revert, iterate, or accept the change and rebuild the growth plan.
- Bring the evidence to Product quickly. Avoid blame. Be precise.
Sam also makes a hard-but-useful point: even if CAC is now 5×, the test can still be valid. It may be the clearest proof that the product is not scalable in its current state (with the old growth method). That’s not a marketing failure. That’s a company-level decision moment.
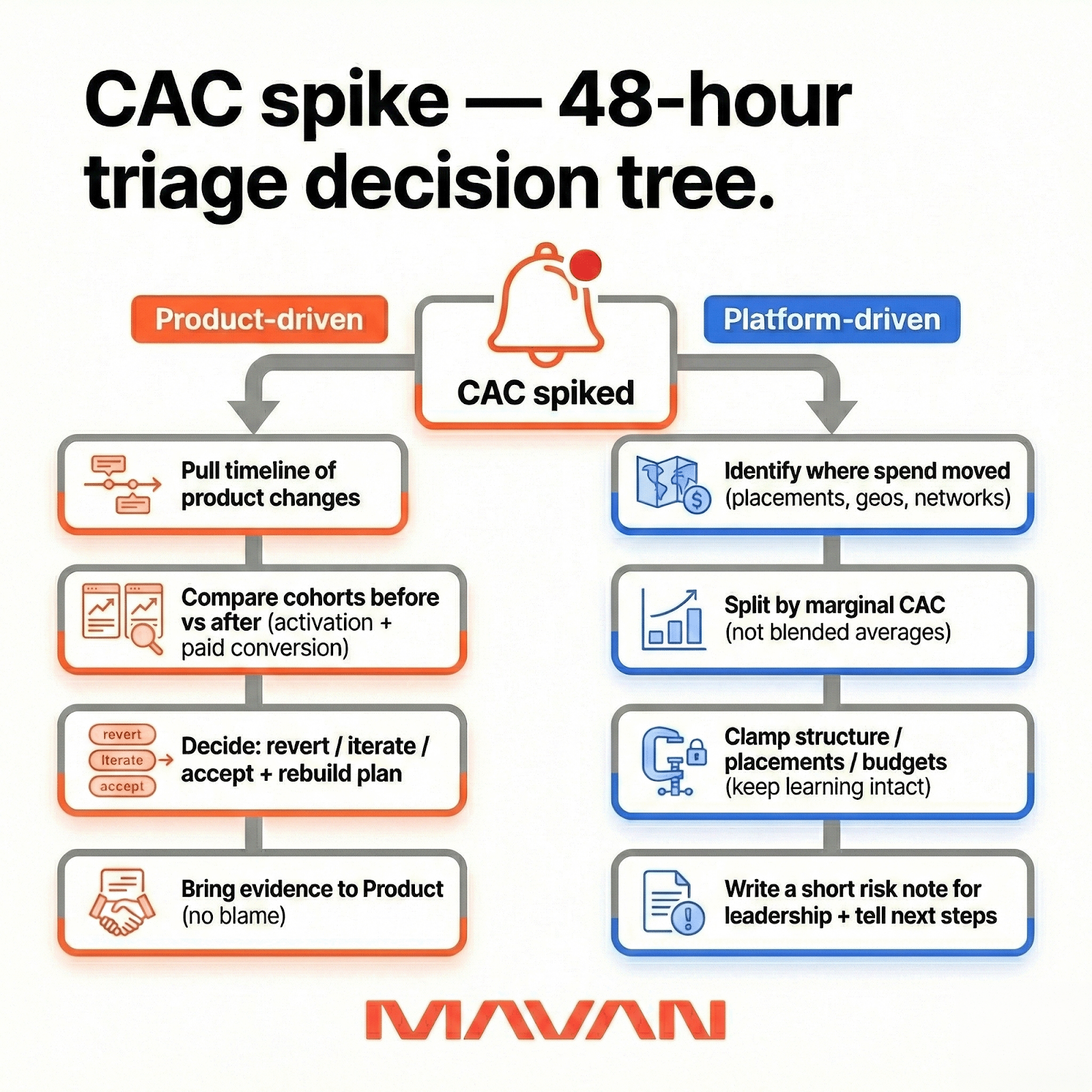
Platform-driven CAC spikes
Sometimes your campaign decides to do something different overnight — after months or years of history. Sam’s example is Meta expanding inventory again on iOS after privacy-era restrictions, using fingerprinting approaches that reopened that supply. Suddenly, campaigns can surge into placements you didn’t expect. Budget goes “gangbusters.” Traffic quality can shift. CAC spikes.
This is where teams panic-change everything. That usually makes it worse.
What we do in the first 48 hours for platform-driven CAC spikes:
- Identify where spend moved (placements, geos, networks). Don’t debate vibes.
- Split results by marginal CAC, not blended averages. Marginal tells the auction story.
- Clamp down on the leaks (structure, placements, budgets). Keep learning intact.
- Write a short risk note for leadership. Say what changed and what we’ll do next.
What boards ask — and what we show to earn trust
Sam says boards ask three things when CAC rises:
- What happened? (What did we do? What changed?)
- What’s the time to resolution? (Are we already moving?)
- What’s Plan B? (If this fix fails, what’s next?)
And we show a one-pager — our One-Page Truth — to keep things clear and concise.
It includes: funnel by cohort (acquisition → activation → week-4 retention → monetization), marginal CAC by channel and cohort, experiment status and impact, and a compact LTV projection. Those widgets connect a top-of-funnel test to a downstream dollar.
This turns potential panic into an accountable plan.
Why chasing CAC alone fails
We chase CAC because it’s visible. It shows up first. Spend, CPMs, installs — they stare at us daily. Product leaks sit downstream. So teams reflexively chase creatives, channels, and bidding tweaks. It feels productive. It also often fails.
Sam names the human component of this problem: leadership wants the lowest costs, so they anchor on the first numbers platforms show them. CPI. Cost. Installs. But in many businesses, revenue concentrates.
For instance, in mobile gaming, Sam calls out how a small group drives a huge share of value. If we optimize for cheap volume, we often open the floodgates to the wrong users.
Three reasons trying to fix CAC doesn’t work
1) Creative churn becomes an endless substitution cycle. Creative churn is expensive and slow. Winning creatives decay. So teams keep swapping assets, hoping the next one saves the month. That cycle can mask structural product leaks for a long time.
2) New channels come with a tax. New channels require new playbooks and new measurement plumbing. Inventory alone doesn’t help when product fit is weak. It often brings higher CAC and worse retention.
3) Attribution blind spots reward the wrong wins. Teams reward early signals — CTR, installs, signups — because they move fast. The real value shows up later. If we optimize only early signals, we drift away from what builds LTV.
If you can’t tie acquisition tests to activation, week-4 retention, and ARPU, you’re optimizing on early signals alone.
A more honest way to treat CTR
Sam’s take is nuanced. He optimizes channel spend using ROAS and revenue. But when it comes to creative, he focuses on CTR, interactions, and where the platform allocates spend across variants. That’s phase one.
Phase two is the funnel — do those users become ROAS-positive?
That sequencing matters because the platform optimizes fast. Sam notes that networks try to optimize in hours, not 14-day cohort windows. They will lean into a “winner” early.
So we need a system that respects both truths:
- Early signals help us find hooks.
- Downstream signals tell us if the hook is worth scaling.
The hidden trap: speed without discipline
Teams also fool themselves with speed. Sam sees two extremes.
On one side, teams demand 90% confidence. They buy certainty with a lot of wasted budget. On the other side, teams make gut changes daily. They keep campaigns in learning. They inflate costs. Then the results stop meaning what they think.
A quick diagnostic you can run this week
Before we fix CAC with more spend, we ask four questions:
- Does creative ROI persist past week 2 or 4?
- Are marginal CACs rising broadly, or is one outlier?
- Are we getting repeatable experiment wins, or lucky hits?
- Are downstream metrics wired to acquisition tests?
If we hit two red flags, we pause hyper-scaling. Then we move to product experiments first.
The better north star: product-led unit economics
When CAC stalls, we can keep fighting the auction. Or we can change what the auction is buying. We prefer the second path. It’s calmer. It’s also higher leverage.
Raising LTV is the lever that makes higher CAC survivable. It buys auction power, time, and resilience. It’s also practical — not theoretical.
Sam highlights the messiness of reality. Teams can operate the same way for years. Then a platform shift hits. Suddenly they need a new growth model. That’s when many realize they can’t even answer basic questions, because attribution is weak. They don’t know what money came in, or from whom. They can’t tie it back to users, cohorts, or campaigns.
That’s not a tooling problem. It’s a governance problem.
Three product levers that actually move LTV
When we talk about raising LTV, we’re really talking about moving a small set of levers that compound.
1) Onboarding → activation mechanics: Activation is where value becomes real. Small changes here move the funnel fast. Tighten first-use flows. Surface the “aha” moments earlier. Remove friction on the core action. Higher activation increases the share of users who can ever monetize.
2) Monetization design: This is pricing and packaging. It’s also the scaffolding that makes spending feel natural. For games, it can mean store balance and live-ops hooks. For PLG SaaS, it can mean tier design and upgrade triggers. For DTC, it can mean subscription nudges and margin-aware bundles. Monetization design can raise ARPU without chasing more volume.
3) Lifecycle orchestration: Retention is the slow engine behind LTV. This is segmentation and triggered campaigns. It is also product nudges that re-engage high-value cohorts. The highest leverage work ties lifecycle touches to measurable revenue events.
These levers behave differently by business model. That nuance matters. We can’t copy-paste tactics across PLG, DTC, and gaming.
How we operationalize this with Demand Testing
Every team wants higher LTV. But few teams can afford to bet engineering time blindly. So we don’t ask teams to guess. We validate cheaply and fast.
Demand Testing is the method: advertise a prospective feature, measure top-of-funnel demand, then pair it with qualitative interviews to forecast downstream economics. We do the math before we build.
A practical playbook we run (and you can replicate):
- Hypothesis: Define the user problem and the monetization mechanism.
- Mock features: Build a landing page, ad creative, or in-app prototype (no full product).
- Drive targeted traffic: Run paid tests into the mock flow. Keep spend focused.
- Measure top-of-funnel signals: Collect CTR, waitlist conversion, and engagement.
- Qualitative follow-up: Interview responders. Why’d they sign up? How would they pay?
- Extrapolate downstream: Use historical funnel rates to project activation, retention, and revenue. Build conservative and optimistic projections.
- Decision gate: Build only if projections justify the engineering investment.
We like this because it reduces engineering risk. It also aligns Product, Growth, and leadership around one forecast.

Minimum necessary instrumentation
We don’t need a perfect data warehouse to start. We do need a spine.
Minimum instrumentation we rely on:
- Top-of-funnel: impressions, CTR, landing conversion to waitlist.
- Mid-funnel: activation within seven days, time-to-first-value.
- Downstream: week-4 retention, conversion to monetized cohort, ARPU.
- Qualitative follow-up: 8–12 in-depth interviews per test cohort.
We don’t invent new metrics. We use what the product already tracks. The goal is simple — connect a top-of-funnel test to a real downstream dollar.
The gates that keep politics out of the decision
Teams don’t fail because they lack ideas. They fail because decisions become social.
So we use clear gates:
- Top-line signal: landing or waitlist conversion beats a preset threshold.
- Qualitative signal: most interviewees show willingness to pay, or clear intent.
- Projected lift: conservative LTV projection beats cost-to-build within a defined payback window.
If a test fails any gate, we iterate or kill it. That discipline saves engineering time — and political capital.
If you’re feeling squeezed by CAC, you don’t need heroics or miracles. You need gates, curves, and one shared truth.
Make Growth + Product one team without a reorg
When CAC rises, teams get tense fast. That tension is normal and predictable.
Systems often split demand from delivery. Growth owns traffic. Product owns experience. Engineering owns output. Data owns truth. Then everyone fights over the same ratio.
The article’s point is simple: this is less org theory and more operating hygiene. If we want repeatable LTV lifts, Growth and Product must act as one accountable unit. Not two tribes passing notes.
The core rule: one scoreboard to prevent endless arguments
We can’t align our way out of conflicting scoreboards. If Growth optimizes early signals, and Product optimizes roadmap output, we will disagree forever.
So we share one scoreboard. That forces a shared truth about what matters.
The minimum necessary roles
We don’t need a big reorg. We need clear decision rights.
Here are the minimum roles we suggest:
- Product Lead — owns activation and roadmap outcomes. Sets specs and acceptance criteria.
- Growth Lead — owns demand and acquisition. Designs traffic and creative hypotheses.
- Engineering Lead — owns execution velocity. Enables prototypes and safe scaffolds.
- Data / Analytics — owns truth. Ships instrumentation and cohort LTV views.
- Creative / CRO — owns conversion. Links the promise to real value.
This is a systems fix that reduces blame and rework.
The rituals that stop chaos from masquerading as speed
Cadence matters because it changes incentives. If we only meet in emergencies, we train the org to hide problems.
Here’s a lightweight rhythm that fixes this problem:
- Weekly experiment triage (30–60 minutes). Prioritize tests by downstream impact per week of engineering time.
- Biweekly roadmap sync (60 minutes). Review progress against 90-day outcomes.
- Monthly LTV review (60 minutes). Data presents cohort LTV curves and experiment attribution. Invite execs for alignment.
These rituals create a predictable pipeline of experiments and reduce the potential for chaos.
The missing discipline: write down the hypothesis, share learnings
Sam calls out a common failure mode: teams run creative tests, but nobody reviews what happened. The hypothesis gets lost. The “why” disappears. Then we repeat the same mistake in a new format.
His fix is plain: define a hypothesis, capture the methodology, and document conclusions. Then share them with the team. That’s how we build a playbook, instead of a graveyard.
This is compassion-forward, too. When learning is visible, people stop getting scapegoated. The system owns the miss. Then the system improves.
The One-Page Truth to stop arguments
A single shared view should show four things:
- Funnel by cohort: acquisition → activation → week-4 retention → monetization
- Marginal CAC by channel and cohort
- Experiment status and impact (lift, confidence, traffic share)
- A compact LTV projection for experiment responders
Those widgets are the minimum to connect a top-of-funnel test to a downstream dollar. That connection is what de-escalates arguments and prevents misunderstandings.
Governance, measurement, and the investor story
When CAC moves against us, investor pressure usually follows. That’s part of the job. But it does create incentives for clean stories over true ones. But the goal should always be to keep the story honest — preferably while keeping the room calm.
So if we own growth, we will likely have to explain our choices to investors at some point. We should do it plainly. Good governance and measurement make that credibility possible.
What investors actually care about
Investors don’t need a perfect ratio. They need a defensible plan.
Here are some of the questions we see in most board conversations:
- Can we sustain growth at reasonable economics?
- Do we understand sensitivity to privacy and platform changes?
- Are experiments moving durable revenue, not vanity metrics?
- Are we being transparent about assumptions?
It may be tempting to paper over assumptions, but it’s better to say the hard thing first, then show the work.
The three board questions we always hear first in a CAC crisis
Sam is direct about what boards ask when CAC rises:
- What happened — and what did we do?
- What’s the time to resolution?
- If this plan fails, what’s Plan B?
That sequence is useful. It forces us to separate diagnosis from reaction. It also forces contingency planning, which protects runway and trust.
The director-ready dashboard that earns trust fast
Here is a director-ready dashboard, built to respect investor language: runway, sensitivity, and defensibility.
It should include:
- Cohort LTV curves (how value accrues over time).
- Marginal CAC by channel and cohort (not averages).
- Funnel by cohort (acquisition → activation → week-4 retention → monetization).
- Experiment attribution map (each meaningful test tied to an outcome).
- Scenario tables (conservative / likely / optimistic LTV, and CAC tolerance).
- Privacy and risk notes (what we do if the rules change again).
How we talk to leadership without spin or bias
Here is a simple step-by-step on how to tell leaders what is going on without introducing our own biases or spin into the mix:
- Start with the constraint. Say the hard thing first.
- Show the diagnosis. Use the funnel breakdown and the failed hypothesis.
- Show the plan. Demand Testing, experiments, or a creative engine.
- Show the math. Conservative LTV projections and tolerable CAC by scenario.
This is what boards reward: a credible plan over vague optimism.
Governance basics that keep us from relitigating decisions
Governance is not bureaucracy. It’s how we stop re-fighting the same debates.
Here is a practical baseline governance stack to prevent relitigation:
- Decision gates for go / no-go. Tie to payback and test signals.
- An experiment registry. Every test, hypothesis, and outcome is searchable.
- Owner-first accountability for activation, monetization, and lifecycle outcomes.
- Regular investor touchpoints — monthly LTV reviews and quarterly scenario planning.
When we do this well, messy debates become predictable choices. That’s what reduces panic.
What to do when CAC plateaus
When paid CAC plateaus and creative wins feel inconsistent, we should stop guessing. We should run three Demand Tests in 30 days. We do it with modest ad spend, 8–12 qualitative interviews per test, and conservative downstream projections. Then we present results with cohort LTV curves and a go/no-go recommendation.
Raise LTV first — it buys you the auction power to win.
The 30-day plan we actually follow
Week 1 — pick the right three bets
We write three crisp hypotheses. We define the user problem and monetization mechanism. Then we pick the fastest way to mock value.
- Hypothesis (problem + mechanism)
- Mock the feature (landing page, ad creative, or in-app prototype)
- Minimum instrumentation (so the test stays honest)
Week 2 — buy signal, not volume
We drive targeted traffic into each mock. We keep spend controlled. We collect top-of-funnel signals and responder lists for interviews.
- Measure CTR, waitlist conversion, and micro-engagement
- Start scheduling qualitative interviews immediately
Week 3 — do the interviews, then do the math
We run 8–12 interviews per test cohort. We ask why they signed up, what value they expect, and how they’d pay. Then we project activation, retention, and revenue using historical conversion rates.
Week 4 — decide and act
We apply clear gates. We build only when projected lift justifies engineering time within the payback window. If a test fails, we iterate or kill it.
- Top-line signal beats your preset threshold
- Qual shows willingness to pay or clear intent
- Conservative projection clears cost-to-build in-window
The behavior shift that makes this work
Sam is adamant here: we need a hypothesis, a test method, and captured learnings. Otherwise, we keep re-running the same experiment in a new costume. We also can’t “micro-tweak” daily at scale. At meaningful spend, we steer a cruise ship: we can’t pivot at a moment’s notice. We need fewer, clearer moves.
The three objections we hear most
- “We don’t have engineering bandwidth.” Don’t build first. Use no-code mockups, landing pages, or concierge flows. Demand Testing was designed for constrained teams.
- “We can’t change product fast enough.” Ship smaller experiments. Prioritize tests with shallow builds and deep commercial learning.
- “Won’t this add overhead?” A little discipline reduces firefighting. It also stops wasted builds. These fixes are organizational. They require clarity and a shared scoreboard.
An If-Then plan for when your CAC plateaus
If CAC plateaus for a month and creative wins feel inconsistent, then run three Demand Tests in the next 30 days. Pair each test with 8–12 interviews. Ship a one-page readout with cohort LTV curves and a go/no-go call.
If you’d like help sketching those three Demand Tests and the one-page dashboard, book a 15-minute call with us. We’ll produce a rapid Demand Testing sketch and a 3-point diagnostic you can take to your exec team.
Frequently asked questions about LTV and CAC
Isn’t raising LTV too slow to help with immediate needs?
No. We don’t need a multi-quarter rebuild to get signal. We need a small set of high-impact experiments. Demand Testing can produce signal in weeks, not quarters.
How long does a Demand Test take?
A focused test — from mock to qualitative interviews — can run in 2–4 weeks with small spend.
How much does Demand Testing cost?
Costs vary with traffic needs and creative. The point is cost control. It’s far cheaper than building a full feature with uncertain payoff.
We lack engineering bandwidth. Can we still validate?
Yes. We use landing pages, concierge flows, or no-code prototypes. We also use feature flags and lightweight scaffolds. Demand Testing was designed for constrained teams.
How do privacy changes affect this playbook?
They increase the value of higher LTV. We should focus on first-party data, cohort measurement, and more resilient acquisition channels.
What does success look like after 90 days?
Clear go/no-go decisions on 3 to 5 prioritized experiments, at least one validated LTV lift, and a one-page dashboard investors respect.
When we say “LTV,” which LTV do we mean in practice?
Sam McLellan (VP of Growth, MAVAN) uses gross LTV because it’s easiest to calculate. He removes platform fees like Apple and Google, since those hit immediately. Then he anchors to a payback window the company can actually tolerate.
When we say “CAC,” which CAC do we mean?
Sam’s bias is to include every real cost he reasonably can — tools, personnel, and operating costs. That approach demands attribution and financial models that can support it.
What’s the most common Demand Testing trap?
Overestimating demand because we want the idea to be true. Sam’s view is simple: you often only learn the truth when real users arrive — and then lapse fast if the product isn’t meaningfully different. That result is still useful, because it forces the next plan.
What are the first three board questions when CAC rises?
Sam hears three, in order: 1) what happened (and what did we do), 2) what’s the time to resolution, and 3) what’s Plan B if the first fix fails. They want motion and a hedge — not guesses.
How do we avoid CTR theater in creative testing?
We don’t pretend early signals are outcomes. Sam warns against gut-reaction micro-changes that keep campaigns stuck in learning. We write a hypothesis, capture results, and share learnings across geos and cohorts. That’s how creative becomes a system, not gambling.
Book a complimentary consultation with one of our experts
to learn how MAVAN can help your business grow.
Want more growth insights?
Thank you! form is submitted
Related Content
-

LTV:CAC Explained: Fix CAC Spikes by Raising LTV (with Demand Testing Playbook)
CAC rising? Learn a practical LTV:CAC diagnostic, Demand Testing method, and 30-day plan to raise LTV and regain growth control.
-

Disrupting Mobile Gaming: Travis Boatman’s Blueprint for Building with Innovation
What does it take to lead — not just survive — in the evolving world of mobile gaming? Travis Boatman…
-

Navigating the Future of Mobile Gaming: Insights from Travis Boatman’s Journey with Carbonated, Inc.
Key Takeaways: Innovative technologies and frameworks are transforming mobile game development, shaping a future where creativity and technology converge. Building…